Hi SCT team,
I am currently using the sct_label_vertebrae for automated vertebral labeling. However, I have encountered a significant issue likely due to poor T1 data quality. Specifically, the majority of the data cannot be automatically recognized, resulting in the error message: “Automatic C2-C3 detection failed.”
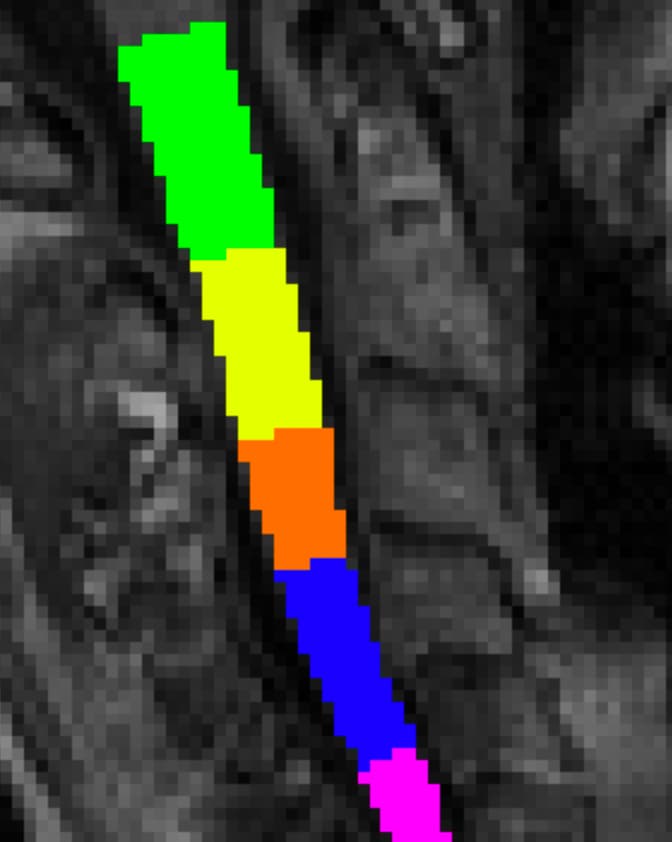
To address this, I labeled the C2/C3, but this approach often resulted in poor identification of C3/C4 or C4/C5, as shown in the attached image.
Given this challenge, if there are any automated solutions or best practices that you could recommend for improving the accuracy of vertebral labeling. Is providing a discfile the only option available to enhance the identification process? (cuz I have hundreds of data  )
)
Thanks!!!
Subj001
Subj002
 t1_spinal.nii.gz
t1_spinal.nii.gz (5.9 MB)
t1_spinal_seg.nii.gz (25.6 KB)
@Xiaomin_Lin The discs are difficult to identify in these images. Do you have another contrast by any chance? Even the localizer could do a better job. If you do, please send them along and I’ll give it a try.
@jcohenadad Thanks for your reply, but sry I don’t have other images, T1 is the only one I have that covers the spinal cord. So do I have to manually label the discs of these images?
This is surprising, as every MRI session starts with a localizer. Are you 100% sure you don’t have the localizer images? These would simplify the labeling process.
If not, I’ll discuss it with my team to see if we can find a solution.
@jcohenadad Sorry for the confusion. Our dataset indeed does not contain localizer scans because the data comes from public databases. Perhaps, considering the privacy of the subjects and the usage rate of the localizer data, the official sources did not provide them.
I see. What public databases do your data come from?
@jcohenadad A dataset from China. If you need data for testing, I can send you some data that cannot be automatically labeled.
We might be able to quickly re-train a model to accommodate these data. If you’re saying these are public datasets, then we should be able to access them. Can you please point us to these datasets?
Hi Julien @jcohenadad Thanks for your help. But I’m very sorry, this database is currently not accessible outside of China. 
However, I have asked Professor Joe Yazhuo Kong, and he has permitted me to send you some of the data. I wonder if this would be acceptable.
apologize again, this situation is beyond my control.
However, I have asked Professor Joe Yazhuo Kong, and he has permitted me to send you some of the data. I wonder if this would be acceptable.
Yup! Definitely acceptable.
Cheers